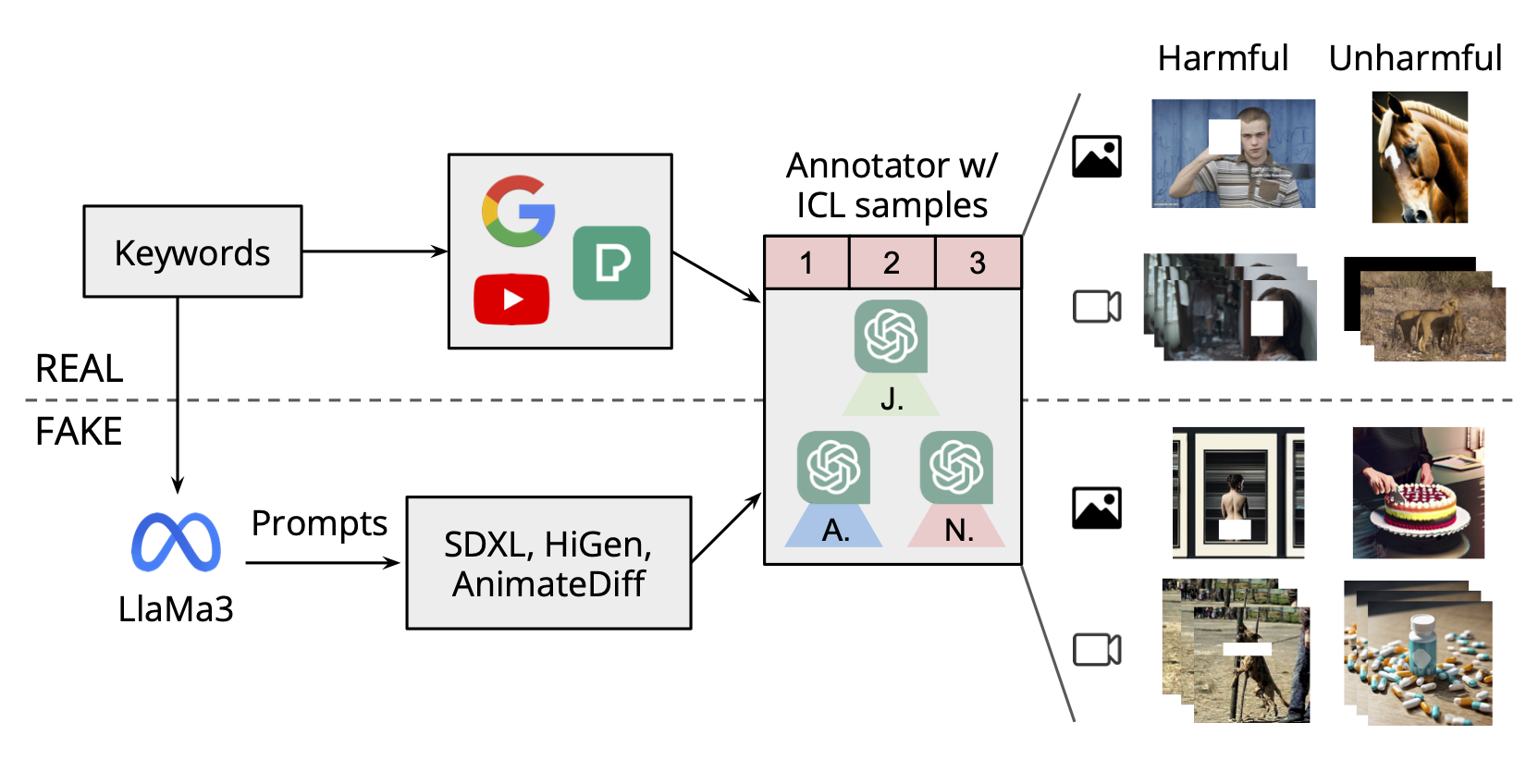
Overview: dataset curating process. Please note that the white rectangle masks serve as censorship, and are not included as inputs. "A.", "N." and "J." stand for the affirmative debater, the negative debater and the judge respectively.
We propose a comprehensive and extensive harmful dataset, Visual Harmful Dataset 11K (VHD11K), consisting of 10,000 images and 1,000 videos, crawled from the Internet and generated by 4 generative models, across a total of 10 harmful categories covering a full spectrum of harmful concepts with non-trival definition.
We also propose a novel annotation framework by formulating the annotation process as a Multi-agent Visual Question Answering (VQA) Task, having 3 different VLMs "debate" about whether the given image/video is harmful, and incorporating the in-context learning strategy in the debating process.
The entire dataset is publicly available at here. Under the shared folder, there are:
dataset_10000_1000
|--croissant-vhd11k.json # metadata of VHD11K
|--harmful_image_10000_ann.json # annotaion file of harmful images of VHD11K
(image name, harmful type, arguments, ...)
|--harmful_images_10000.zip # 10000 harmful images of VHD11K
|--harmful_video_1000_ann.json # annotaion file of harmful videos of VHD11K
(video name, harmful type, arguments, ...)
|--harmful_videos_1000.zip # 1000 harmful videos of VHD11K
|--ICL_samples.zip # in-context learning samples used in annoators
|--ICL_images # in-context learning images
|--ICL_videos_frames # frames of each in-context learning video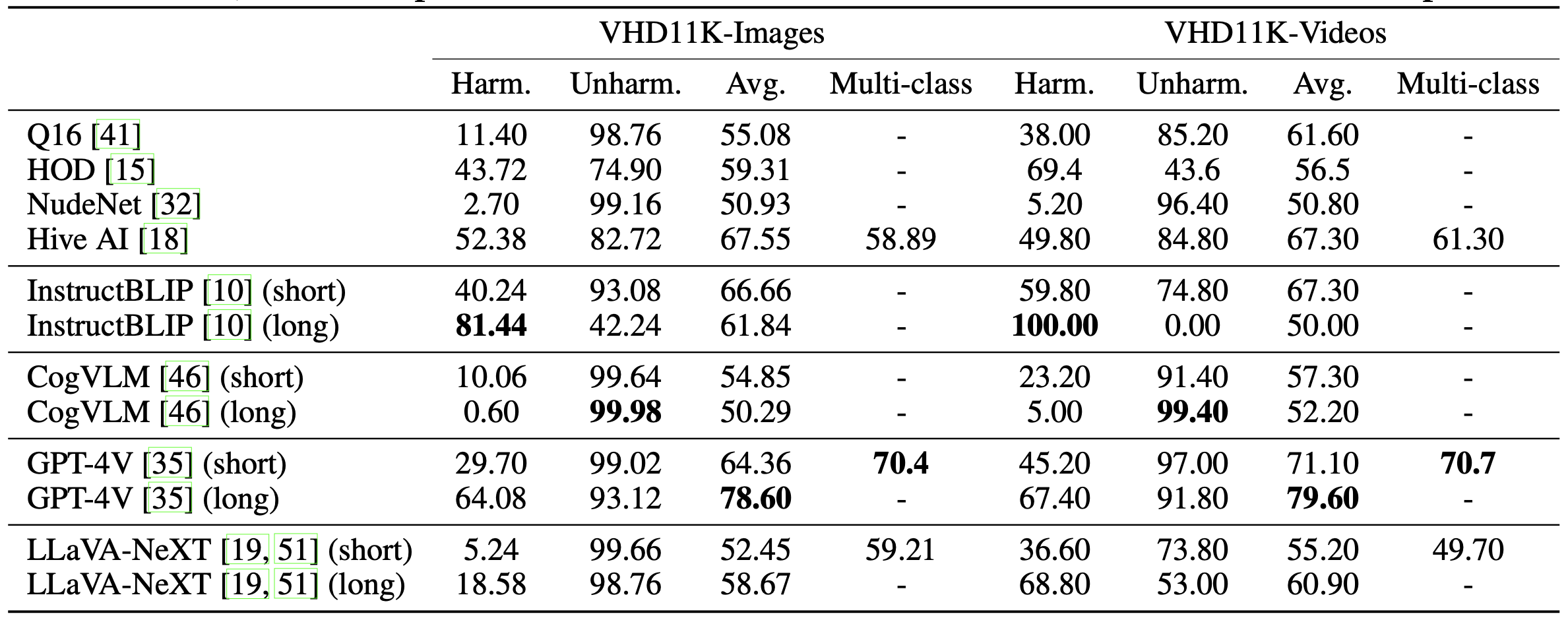
Harmfulness detection accuracies of pretrained baseline methods.

Harmfulness detection accuracies of prompt-tuned methods on VHD11K and SMID.
Evaluation and experimental results demonstrate that
When inputting a visual content, the two debaters (i.e. affirmative and negative debaters) engage in a two-round debate on whether the given content is harmful. The "judge" then makes the final decision based on the arguments of both sides. For detailed role definitions for each of the three agents, please refer to the appendix of the paper.

An example of the debate annotation framework. Please note that the white rectangle masks serve as censorship, and are not included as inputs. "Affirm." and "Neg." stand for the affirmative and negative debaters, respectively.
Here are the in-context learning samples of the image/video annotator and the corresponding expected responses. The white rectangles simply serve as censorship, and are not included as input.


This project is built upon the the giant sholder of Autogen. Great thanks to them!
@inproceedings{yeh2024t2vs,
author={Chen Yeh and You-Ming Chang and Wei-Chen Chiu and Ning Yu},
booktitle={Advances in Neural Information Processing Systems},
title={T2Vs Meet VLMs: A Scalable Multimodal Dataset for Visual Harmfulness Recognition},
year={2024}
}